TestGenEval: A Real World Unit Test Generation and Test Completion Benchmark

The code LM community primarily relies on benchmarks like HumanEvalFix and TestEval, for measuring test generation capabilities. Unfortunately, common benchmarks are often toy programs that do not capture the complexity of real world repositories. We seek to adapt SWE-Bench into a test generation benchmark on more complex, real-world repositories.
We design TestGenEval, a benchmark of 1210 Python test files and their corresponding code files. We measure a variety of metrics, including compile@k, pass@k and coverage improvement for generating the first test, last test and an additional test given the code under test.
The benchmark was constructed as follows:
We run TestGenEval on a variety of SOTA models. These include popular open source models ranging from Llama 3.1 8B, 70B along with GPT-4o (the current SOTA closed source model). For full test suite generation, Llama 3.1 405B has the highest pass@1, but interestingly still lower coverage than GPT-4o. This means that despite generating more passing tests, the tests generated by Llama 3.1 405B tend to be lower quality than GPT-4o. This is also reflected by the higher mutation score of GPT-4o generated test suites.
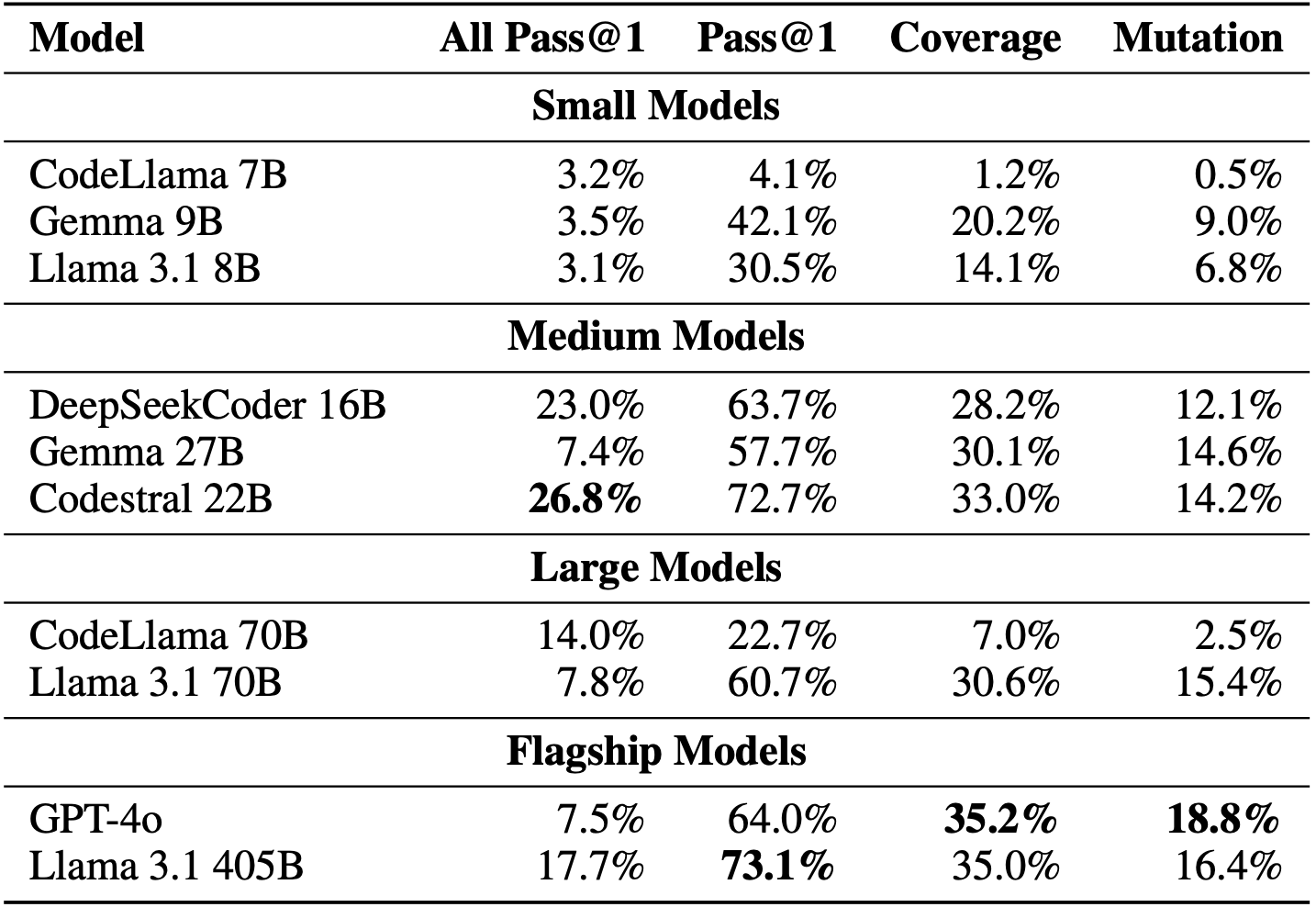
For test completion, we also observe a similar trend. Of all models, Codestral generates the most passing tests for all three settings (with the exception of pass@1 for first test generation, where GPT-4 generates more passing test). However, similar to test generation, GPT-4o is able to achieve higher coverage than Codestral generated tests. This illustrates that GPT-4o tests tend to be higher coverage than Codestral generated tests.
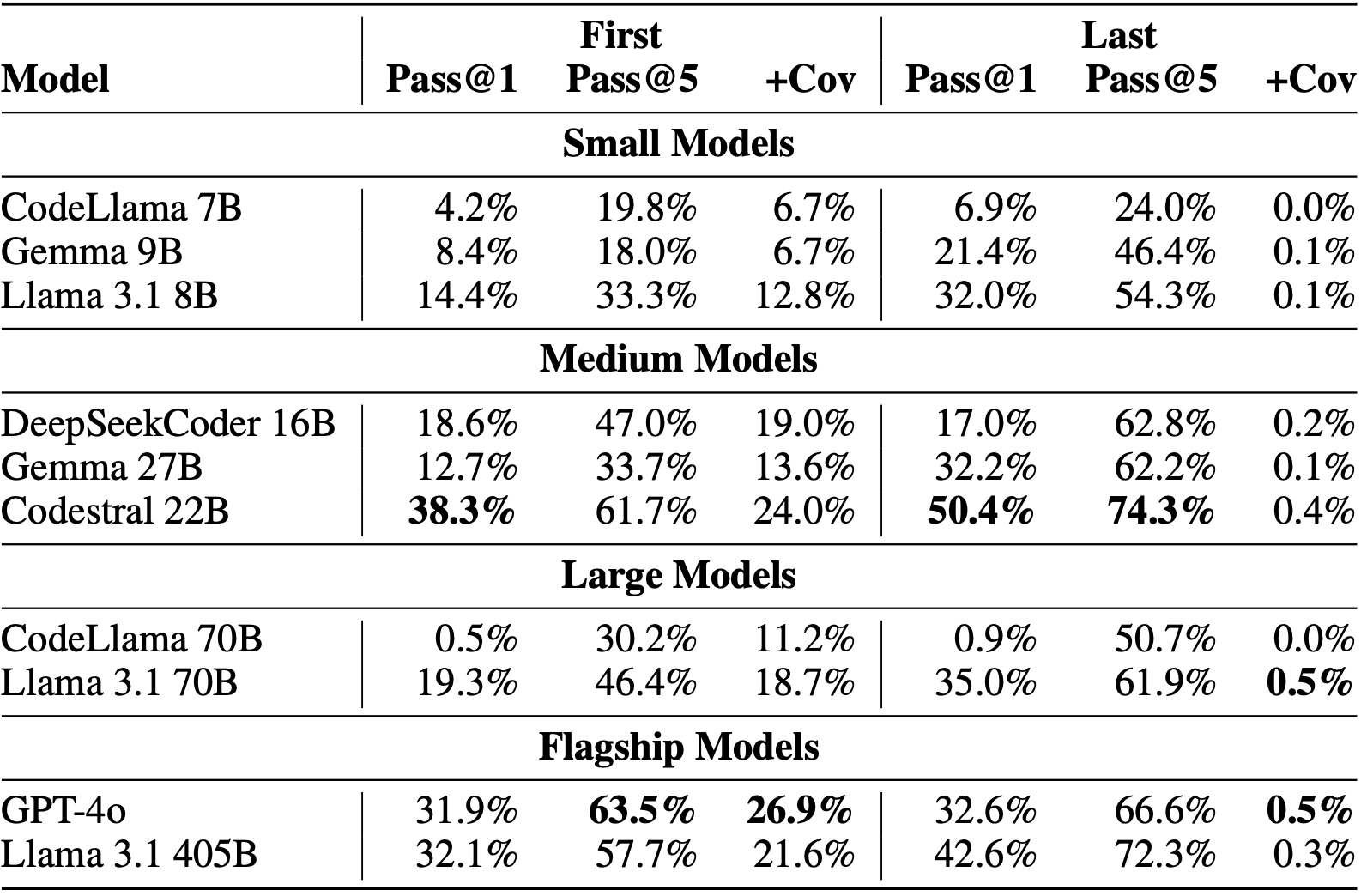
We measure the correlation between TestGenEval and HumanEval, a popular code generation benchmark, and TestEval, a popular test generation benchmark. We find that there is a moderate positive correlation for both benchmarks, however there are some outliers: models such as Gemma 9B-it have trouble following the TestEval prompt, but do well on TestGenEval.
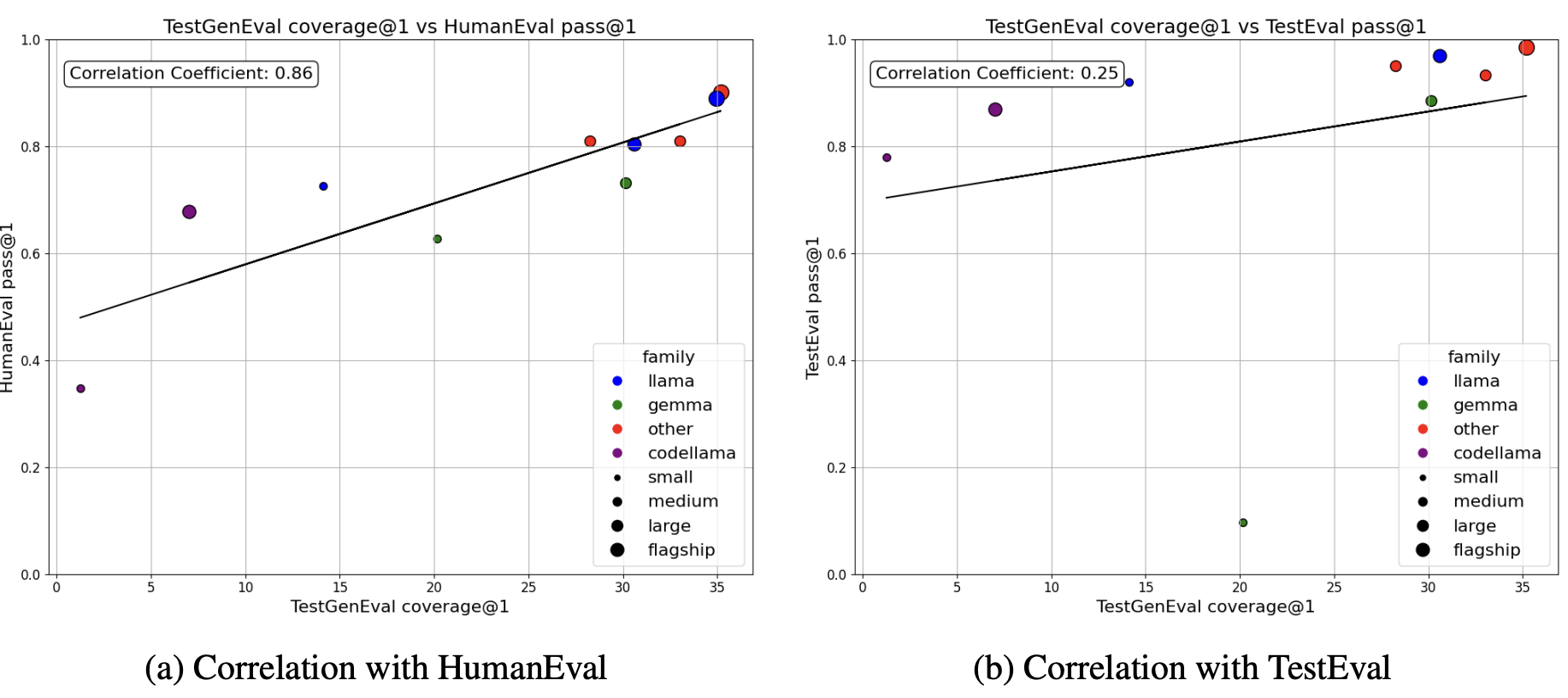
We also bucket common errors on TestGenEval. We find that models frequently fail to generate tests that follow the prompt format or have asserts. Other common errors include assert errors, timeout errors, and value errors.
Our benchmark also consists of many no solve problems and one solve problems. The figure shows an example of a no solve case, where generating a test requires additional file level context, or complex mocking of all the classes and methods invoked.

Overall, we believe that TestGenEval introduces a new chapter in test generation evaluation! We introduce the first test generation benchmark at the file level, across complex real world projects.
@misc{jain2024testgeneval,
title={TestGenEval: A Real World Unit Test Generation and Test Completion Benchmark},
author={Kush Jain and Gabriel Synnaeve and Baptiste Rozière},
year={2024},
journal = {arXiv preprint arXiv:2410.00752},
}